반응형
Prometheus?
Metrics 모니터링 시스템
- Metrics 모니터링 솔루션이다.
- Metrics 모니터링 특성상 Logging(ELK, CloudWatch), Tracing(OpenTracing, jager, zipkin, pinpoint) 과는 용도가 다른 점을 알고 사용해야 한다.
아키텍처 (Prometheus 컴포넌트)
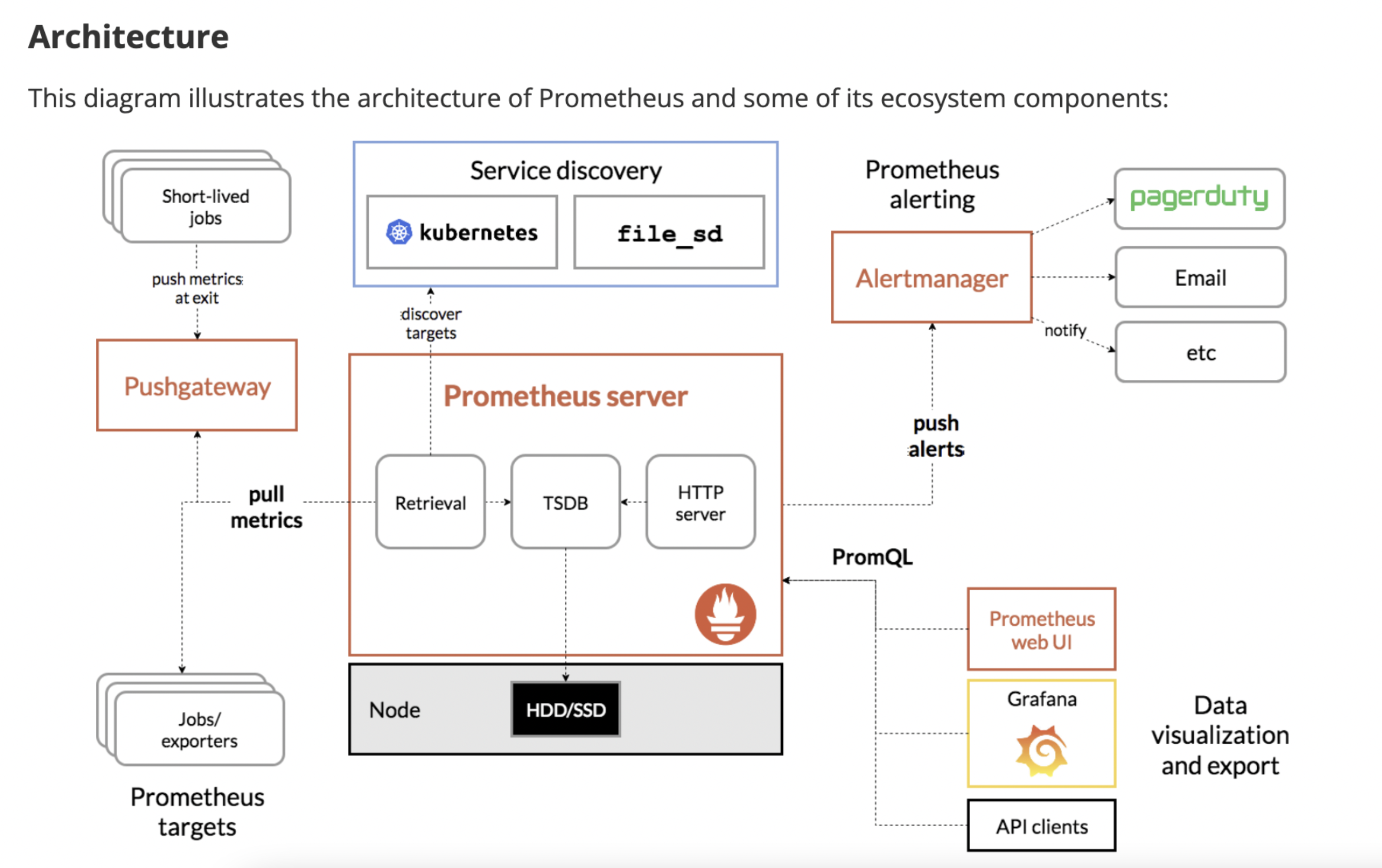
1. Exporter / Job
모니터링 대상의 Metric 데이터를 수집하고 중앙 집중 서버인 Prometheus Server가 Metrics 데이터를 가져갈 수 있도록 API Endpoint 을 제공
- node-exporter: 노드의 CPU, Memory, Network bandwidth 등 metrics 정보를 수집
- jmx-exporter: JVM metrics 수집 (tomcat, kafka, cassandra …)
- kafka-exporter, mysql-exporter, redis-exporter 등 다양한 exporter가 이미 제공되며, 커스텀도 가능
- 공식적으로 제공하는 Exporters → https://prometheus.io/docs/instrumenting/exporters/
2. Prometheus Server
- Retrieveal가 Exporter에서 제공하는 API를 통해서, Metrics를 Pull 해와서 -> Prometheus Server 내의 TSDB에 저장.
- 특이점은, 대다수의 모니터링 시스템과 같은 Push 방식이 아닌 Pull 방식으로 Metrics 데이터를 수집
- 대부분의 모니터링 도구가 Push 방식으로, 각 대상 서버에 Agent를 설치하고, Agent가 데이터를 수집해서 중앙 서버로 전송하는 방식을 사용.
- 반면, Prometheus의 경우에는 Pull 방식으로, 중앙 집중 서버에서 각 target 서버로 부터 (Exporter를 통해) 메트릭 데이터를 수집해가는 방식
- 모든 메트릭 지표를 전송하지 않아도 되므로, 트래픽 및 오버헤드 감소 및 Prometheus Server의 장애가 애플리케이션에 영향을 미치지 않는 장점.
- 단점으로는 중앙 집중 서버인 Prometheus Server에서 각 대상 서버에 대한 정보를 알고 있어야 하는데, Service Discovery를 두어서 해결
3. PushGateway
- pull 할 수 없는 상황에서 pull 방식이 아닌 Push 방식으로 metrics를 전송하기 위한 컴포넌트
- Exporter와 동일한 역할을 하지만, pull 방식이 아닌 Push 방식으로 동작하는 컴포넌트라고 생각된다.
- 예를 들어, 배치 잡 등 prometheus server가 exporter로부터 pull 하기도 전에 파드가 종료되어서, Prometheus Server(Retrieval 모듈)이 메트릭 정보를 읽어가기 전에 종료되는 경우
- Prometheus Server에서 메트릭 정보를 읽어갈 Exporter가 Prometheus Server에서 접근할 수 없는 곳에 있는 경우
4. AlertManager
- 설정된 Rule에 따른 알림 Notification 담당
- Slack 등에 연동해서 알림 시스템 구축 가능
- ex) 임계치를 넘어서면 알림 발송 등
- Cpu usage 70% 이상이 되면 알림을 발송하는 등
- 보통 Grafana를 연동해서 쓰는데, Grafana에서 제공하는 알림 시스템을 사용하는 걸로 보임
프로메테우스의 주의사항
- Prometheus Metrics는 정확하지는 않음
- 정확한 수치보다는 추이 정도를 확인하는 용도로 사용하는 것을 추천한다고 합니다
- 메트릭 데이터 유실이 발생할 수 있는 등을 알고 사용해야 한다.
- Prometheus은 장기 보관(Long term Storage) 및 고가용성(HA)이 어려운 한계가 존재.
-> Cortex, Thanos, Victoria Metrics 등 솔루션을 같이 활용해서 장기 보관 및 고가용성 해결- Thanos
- 같은 오픈소스로, 여러 개의 프로메테우스로부터 매트릭을 조합해서 타노스에서 전체 프로메테우스의 메트릭을 볼 수 있도록 해 주고, 수집된 메트릭을 스케일이 가능한 스토리지에 저장해서 특정 프로메테우스 인스턴스가 다운이 되더라도 그 인스턴스가 담당하는 메트릭을 조회할 수 있도록 해준다.
- Victoria Metrics
- Victoria Metrics는 확장 가능한 모니터링 솔루션 및 시계열 데이터베이스의 역할을 수행.
- Prometheus의 장기 저장소의 역할을 수행 가능.
- Prometheus Query API를 지원해서, Grafana에서 Prometheus 대안으로 사용 가능. (위의 Prometheus 아키텍처에서, Prometheus Server의 대안으로 활용)
- Thanos
반응형
'DevOps & SRE' 카테고리의 다른 글
| [배포 전략]: Recreate, Rolling Update, Blue/Green, Canary 배포가 뭐죠? (0) | 2021.02.13 |
|---|