Cassandra DB 성능 개선기 (1) - Read ahead와 Disk I/O
회사에서 플랫폼을 운영하면서 겪은 장애와 개선한 점들을 공유해보려고 합니다.
Cassandra DB를 운영하면서 발생한 이슈이지만, 내용이 Cassandra DB에만 국한되지 않는 내용인 점 먼저 말씀드립니다.
장애 발생
플랫폼을 운영하던 중, 급격하게 증가하는 데이터로 인해 요청이 밀리는 장애가 발생하였습니다.
- 평소 한자리 ms의 Latency로 API를 제공하던 중, 갑자기 요청을 처리하기 위한 Latency가 100ms 이상으로 밀려버리는 장애가 발생하였습니다.
- 빠르게 데이터를 서빙해야하는 데이터 플랫폼 특성상, 낮은 Latency로 데이터를 제공해야 합니다.
장애 원인
- 장애 원인은 Disk I/O 사용량 (Disk Usages이 아닌, Disk I/O Usages입니다) 급증으로 인해서 Disk IO이 병목이 발생하고, CPU I/O Wait가 증가해서 요청이 밀리게 되었습니다.
먼저, 장애 대응을 위해서 빠르게 Cassandra 장비를 증설하고, Disk IO 사용량에 대한 모니터링 및 사용량에 대한 단계별 알림을 추가해서, 장애가 발생하기 전에 미리 대응할 수 있는 시스템을 구축하는 긴급 대응을 진행하였습니다.
이후 갑자기 Disk IO가 급증한 이유는 무엇인지 원인 파악 및 해결 방안을 고민하였습니다.
갑자기 Disk IO가 급증한 이유가 뭐지?
Disk I/O 부하가 높은 이유에 대해서 다양한 방면에서 고민하던 중, 당시 Cassandra DB 서버의 Linux Page Cache 히트율이 매우 낮다는 것을 확인하였습니다.
Linux Page Cache란?
디스크는 다른 장치들에 비해서 느립니다. 이런 상대적으로 느린 디스크에 대한 요청을 좀 더 빠르게 처리하기 위해서 Linux 커널은 남는 메모리의 일부를 디스크 요청에 대한 캐싱 영역으로 할당해서 사용하게 합니다.
이를 통해 이후에 동일한 데이터에 대한 요청이 있을 때는 메모리에서 데이터를 반환하여 디스크 I/O를 줄일 수 있습니다
이때 사용되는 메모리 영역을 Page Cache라고 합니다.
Cassandra DB Read 동작 방식과 Page Cache
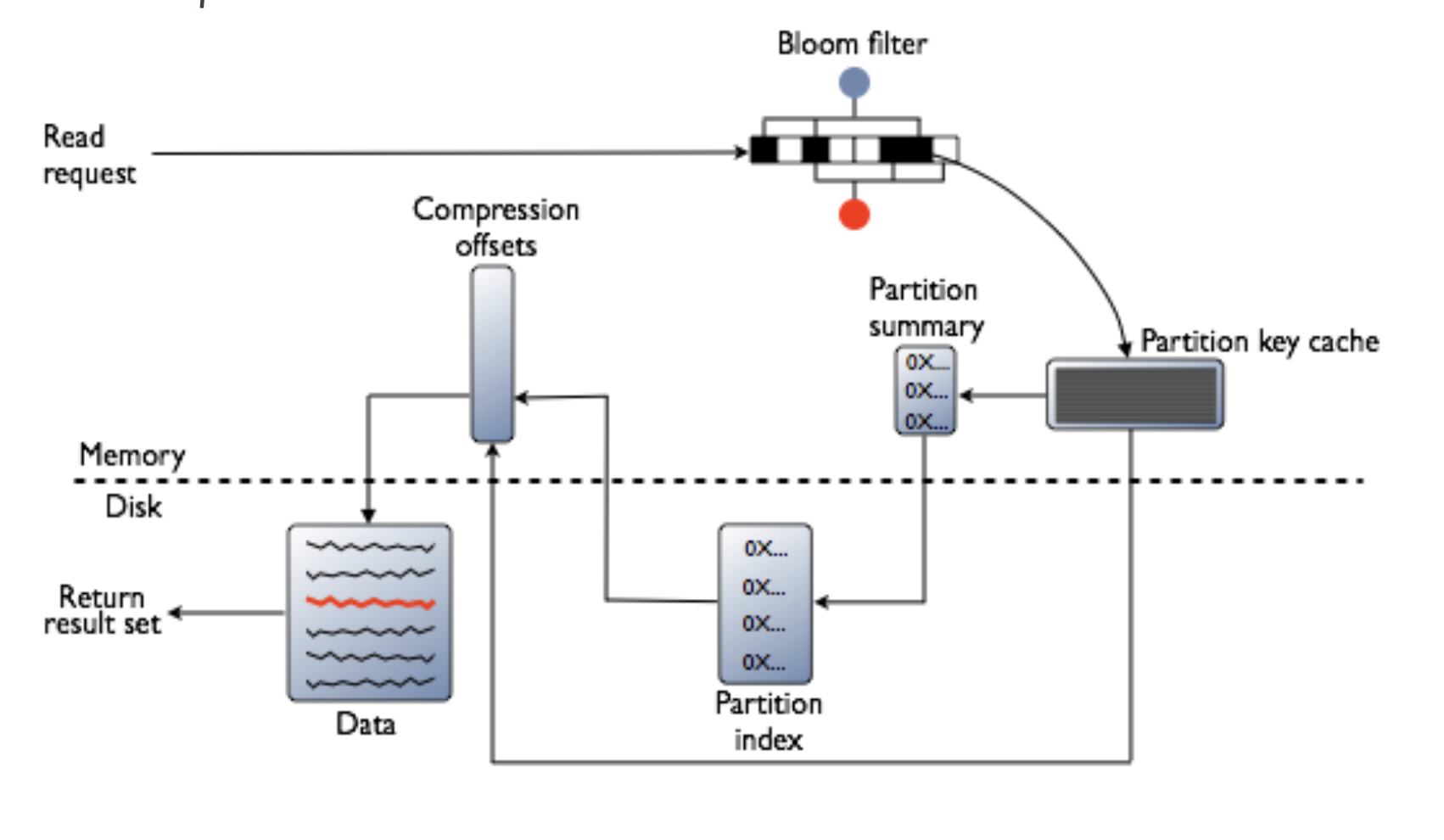
Cassandra에서 존재하는 데이터를 읽으려면, 디스크로부터 데이터를 읽어야 합니다. (Data가 저장된 위치 등은 캐싱할 수 있지만, 데이터를 Fetch 하기 위해서는 디스크로부터 데이터를 읽어와야 하는 구조)
Cassandra DB에서 Row cache 라는 캐시를 선택적으로 사용할 수 있지만 문제가 된 데이터의 사용 패턴 특성상 유저 단위의 넓은 범위의 데이터로, 매우 낮은 히트율로 인해서 오히려 오버헤드만 증가하여 Row Cache를 사용하고 있지 않습니다.
이런 구조에서, Cassandra DB에서 데이터 읽기 시, Page Cache는 1차 캐시 역할을 합니다
Cassandra DB 서버에서 Linux Page Cache 히트율이 낮다는 것을 확인하고, Page Cache 히트율이 낮은 이유와, 히트율을 높이기 위한 방법을 고민하던 중, 서버의 Linux Read ahead에 설정에 대해서 높게 잡혀있는 것을 확인하였고, 해당 설정값을 튜닝해서 Disk I/O 부하를 개선할 수 있을 것으로 생각하였습니다.
Read ahead란?
Read ahead란, 파일 시스템에서 Prefetch 개념으로 순차적인 읽기 작업 중에 OS에서 미리 읽어서 Page Cache에 저장하는 개념으로 순차적인 읽기나 대량의 데이터를 읽어야 할 때 성능을 향상해 주는 기능입니다.
저희 플랫폼으로의 요청 중 다수가 캐시 히트율이 매우 낮은 (일종의 유저 개인화 데이터) 데이터로, 랜덤 액세스 패턴으로 조회하는 패턴으로 사용하고 있었습니다.
이러한 특성으로 인해서, 높은 Read Ahead 설정이 오히려 Page Cache에 저장되는 유효한 페이지의 개수를 감소시키고 이로 인해서 Page Cache 히트율 감소 및 불필요한 데이터 읽기 등 오버헤드를 발생시킨다고 생각하였습니다.
개념상으로는 Read ahead 크기를 낮춰서, 좀 더 많은 유효한 페이지들을 캐싱할 수 있고, 높은 성능을 유지할 수 있을 거라고 생각했고 검증에 들어갔습니다.
Read ahead 크기(read_ahead_kb) 에 따른 Cassandra DB Read Ops 비교
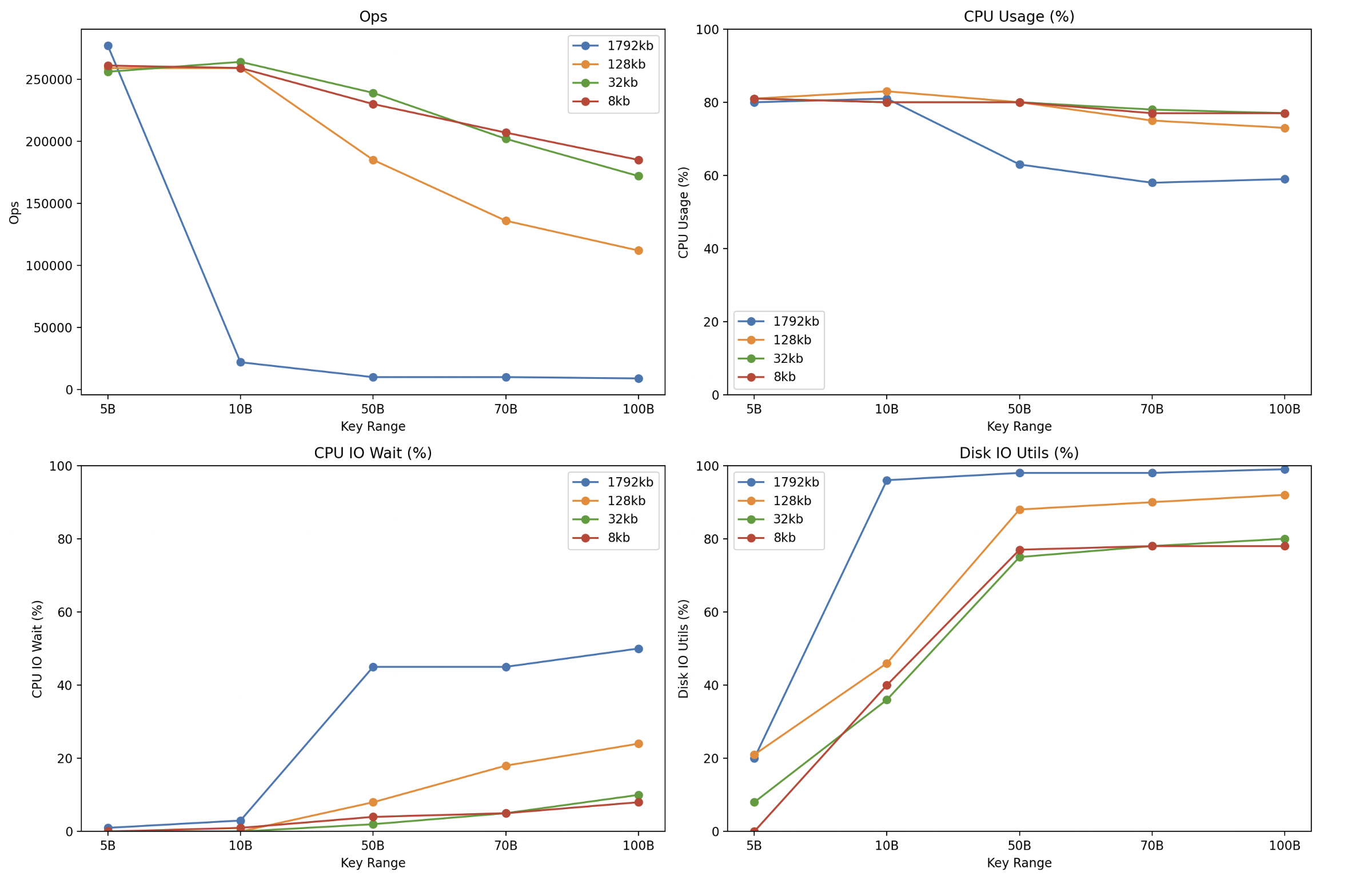
cf) 위에서 Key Range는 일종의 핫 키 개수로, 실제로 조회되는 데이터 개수로 보시면 되겠습니다. (1~N개 중 랜덤의 1개에 대해서 랜덤 액세스를 수행)
- B는 billion을 의미 합니다 (5B = 50억)
테스트 결과는, Key Range가 적을 때는 아직 Page Cache에서 처리할 수 있어서, 높은 Page Cache 히트율 및 Read ahead 크기와 상관없이 높은 성능을 보여주었습니다.
하지만 조회하는 Key Range가 늘어날 수록, 높은 Read ahead 설정은 먼저 Disk I/O가 병목이 되어서, CPU I/O Wait가 증가하고, 이로 인해서 처리량이 급격하게 감소하는 패턴을 보여주었습니다.
개선 내용
위와 같은 검증 결과를 토대로 다음과 같은 개선 작업을 진행하였습니다.
- 랜덤 액세스 비율이 높은 플랫폼 사용 패턴 특성상 적은 Read ahead 크기를 사용하는 것이 유리하다고 판단되어 Read ahead를 일정 수치로 낮춰서 (1792kb -> 8kb), 캐시에서 처리할 수 있는 키의 개수를 늘려, 더 많은 페이지에 대해서 캐싱할 수 있도록 처리할 수 있도록 변경하였습니다.
- (추가적으로 순차적인 접근 패턴에서도 일정 이상의 Read ahead가 결코 성능상 유리하지 않다는 것을 확인하였습니다)
- 다만, Read ahead 설정을 8kb 이하로 줄이기에는 저희가 제공하는 패턴 중 순차 조회도 많은 부분을 차지하고, 요청에 대한 처리 이외에도 Cassandra 내부 동작들이 있기 때문에, 적정 값인 8kb로 설정하였습니다.
- 이외에도 Cassandra DB는 JVM에서 동작하는데, JVM Heap Size를 좀 더 낮은 수치로 적정 값으로 설정해서, 더 많은 메모리가 페이지 캐시로 사용될 수 있도록 개선하였습니다.
이로 인해서 설정 값 튜닝으로만 변경 전 대비 CassandraDB Node당 대략 3배의 랜덤 액세스 가용량을 얻을 수 있었습니다.
이외에도 다양한 개선을 통해서 대량의 데이터 및 트래픽 환경에서 플랫폼을 안정적으로 운영하고 있습니다.
감사합니다.